

One of the questions I am getting from time to time since I started testing FileMaker performance is whether there is any significant difference between performance of text and number fields, how indexing affects speed, and what’s the impact of uniqueness of the existing values. So I tested it and discovered that there is even a case when indexed field can be slower than an undindexed one.
To properly test impact of the three different factors, I prepared a set of 100,000 unique random values. Each value was generated simply by evaluating the Random function. I also made sure that there were no duplicates in the test data set. Then I created 4 number fields and 4 text fields, half of them indexed, half unindexed. I copied the same random data set to 4 fields in 100,000 records – one indexed number field, one unindexed number, one indexed text, and one unindexed text. And finally, I filled the remaining 4 fields in each record with a random selection of the first 100 values.

After preparing the data, I tested performing find in each of the 8 fields. Thanks to having all the values of the same lenght and beginning with decimal separator, I could use the same search criteria in both text and number fields to return all 100,000 records as the result found set. The criteria was: >.0
I also ran all tests three times in a row to minimize impact of caching or other factors that I did not have under control.
When testing with indexed fields and the 1 of 100 data set (typical situation when using values selected from a value list or IDs of related records), the result was quite expectable. Searching in a number field was significantly faster than searching in a text field.
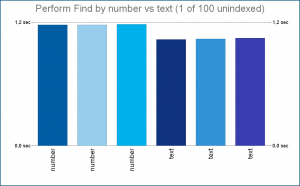
The same test, just with unique values, gave me similar result. Here again, searching in a number field was much faster, and the difference was even bigger than with the 1 of 100 test. This clearly indicates that number index is much more efficient for searches than text index.
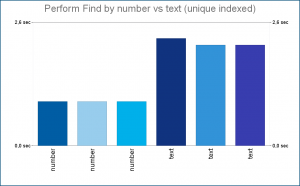
The following test was already a bit more interesting. After switching to unindexed fields, I expected search performance in both number and text field to be about the same. This my assumption was based on the fact, presented by Clay Maeckel in his Under the Hood session at FileMaker DevCon 2016, that FileMaker internally stores numbers as text. So what a surprise it was for me to find out that actually number fields perform slightly worse than text fields when performing finds without index.
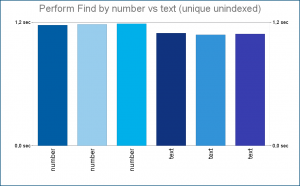
After thinking about it, I believe, although I don’t have it confirmed, that when searching in a number field each value actually needs to be converted to number in order to evaluate the search criteria mathematically, while when searching in a text field a simple text comparison is used, and the extra overhead of dealing with numbers is what’s making them slower when searching without index.
However, the most interesting result popped up at me when I compared all the 8 tests in a single chart:
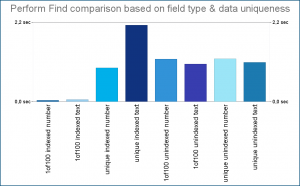
There was no doubt that non-unique values and indexed fields will perform the best. But as you can see in the chart, the absolute worst case is not one of the unindexed searches. The longest search time was measured when searching in indexed text field containing unique values. It was even almost twice as slow as searching in unindexed field.
What does this mean?
When the Get(UUID) function was introduced in FileMaker Pro 12, many developers started to use it to generate unique record IDs. Later few people in the community started pointing out that it’s actually causing significant performance hit in comparison to number-based IDs. I don’t want to deny credit for finding this out to anyone, but I think the first one I read this comment from was Jeremy Bante. In any case, many people confirmed since then that numeric UUIDs perform significantly better than text-based UUIDs and several custom functions appeared to help generating numeric UUIDs, such as this one contributed by Jeremy: https://www.briandunning.com/cf/1246
But have you ever imagined that looking up the text-based UUID in an indexed ID field could be even significantly slower than searching for the same ID in an unindexed field? I have to admit that in this case I have not tested exact value match criteria or Go To Related Records, which would be more relevant for using IDs, and I am actually planning to do that comparison at some point, but it’s good to know that the text index may have significant overhead.
Think about it before turning on index for text fields in general. If you are likely to have repeating values from a value list in your field, having a value index is definitely going to help. If you’re going to store natural text in your field and likely to search for words that appear many times, word index is probably going to be your friend. But if your text field is going to hold unique values, the index overhead is something you may want to avoid.