Claris has recently released FileMaker Pro 19.1.3 and FileMaker Server 19.1.2. The new FileMaker Pro brings some great new features and the new version of FileMaker Server is supposed to be more stable and faster. It also finally brings version for Linux. I have added these new versions to my performance lab and here are my first test results. Linux version seems slightly faster than Windows version, JavaScript is way faster than FileMaker calculation engine, and sorting on server can surprise you as much as it has surprised me.
Lab setup
In order to be able to compare my test results even with the oldest results of my tests I performed on previous versions of FileMaker, I kept using the same test machine as in previous years, the Mac Pro (early 2008). I just could not include the macOS version of FileMaker Server any more, because the minimum maOS version supported by FileMaker Server 19 is 10.14 Mojave and the latest version I could make reliably work on that machine was 10.13 High Sierra.
For now I have performed just a short series of tests, mostly with just 1000 records, using FileMaker Server 18v4 and later, but once I have the complete full test done, I will make the comparison with the old results as well, comparing the latest version of FileMaker with all the previous versions back to FileMaker 12. Now let’s focus on the most recent news.
Linux vs Windows
One of the long awaited features that FileMaker Server 19.1.2 finally turned to reality is the support for on-premise Linux installations. Specifically, the distribution supported and recommended for this version is CentOS Linux 7.8.
In addition to being better priced than Windows especially for hosting providers, Linux has some advantages for technically savvy server administrators, such as command-line control over SSH, not mentioning some core technologies the system is based on. But how does it differ in performance?
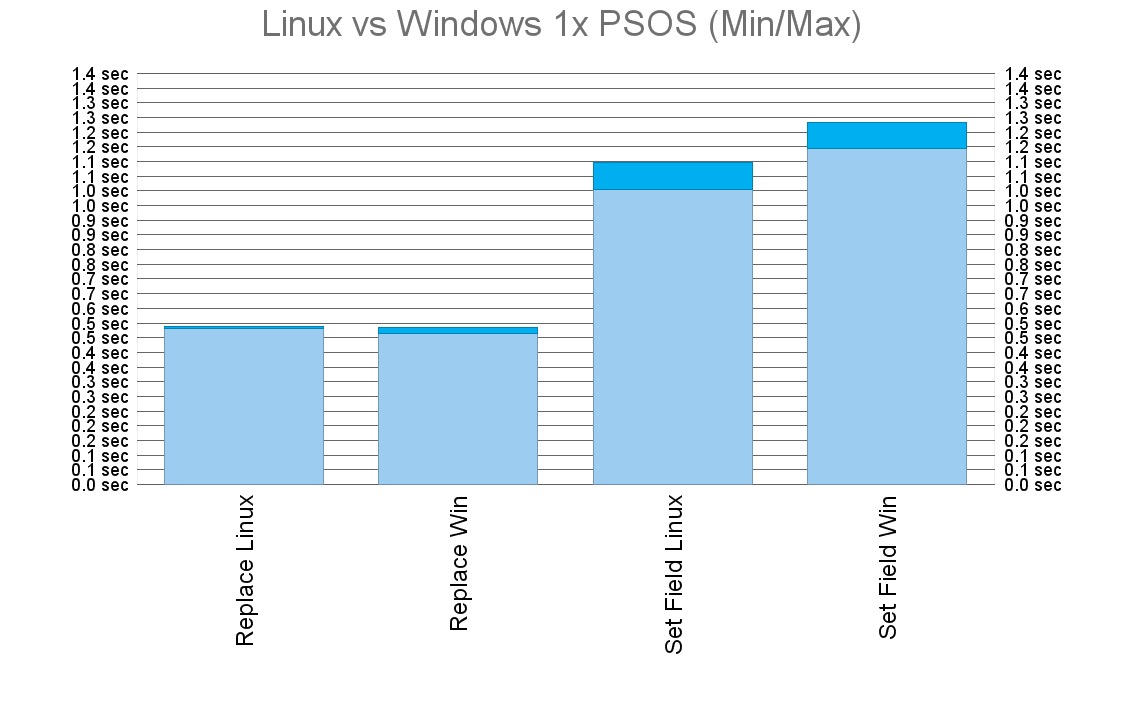
Most of my tests did not reveal any significant difference between Linux and Windows yet, but I have to admit that 1000 records was too small data set to actually show something as many tests completed in less than a second. The test where I could find the biggest differences was modifying all the 1000 records either via Replace Field Contents, or using Set Field in a loop.
Running the test over LAN from a 13-inch MacBook Pro (late 2015) took about the same time with both Linux and Windows version of FileMaker Server:
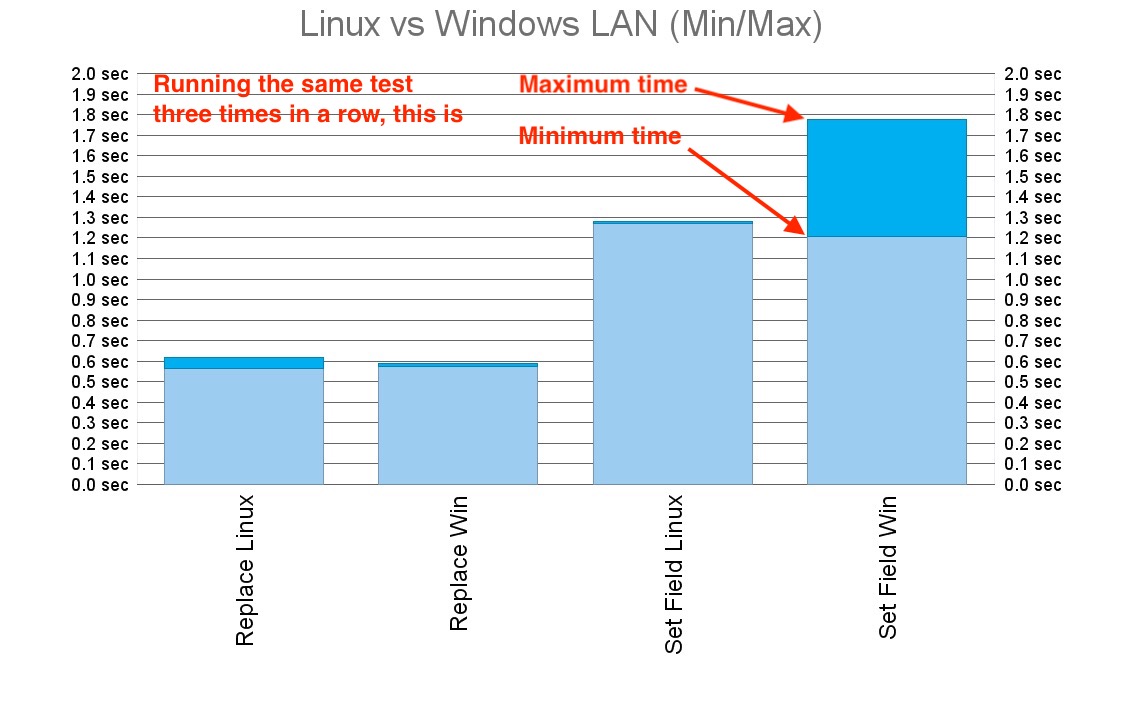
But it seems that here most of the execution time was consumed by the client, which was still the same. When I executed the test on server, it started showing that FileMaker Server may be performing slightly better on Linux than it is on Windows.
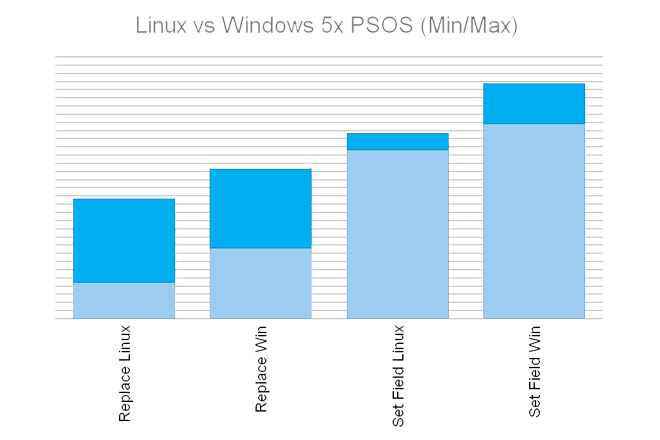
What is the most important for a server software, however, is how it performs for multiple users. And that’s where it starts to be interesting…
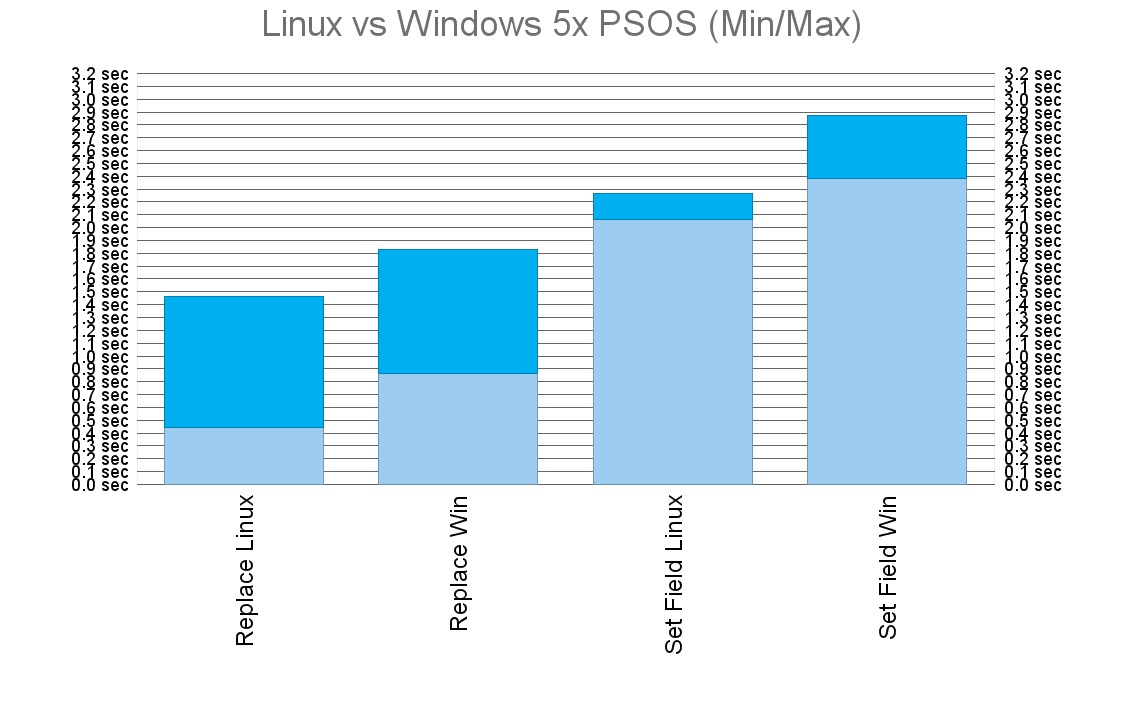
It seems that the on-premise Linux version of FileMaker Server definitely deserves some attention from the performance perspective, especially for larger deployments with many concurrent users. I am eager to see what my following tests with larger data sets and higher number of concurrencies reveal.
FileMaker 19 vs FileMaker 19 vs FileMaker 18
FileMaker Server 19.1.2 is primarily a stability and reliability focused release, so many customers were waiting for it and delaying their upgrade to FileMaker 19. So how does the latest version compare to 18 and the initial release of 19?
It seems that the Draco engine itself, which is the same in both FileMaker Pro and FileMaker Server, performs equally in all these versions:
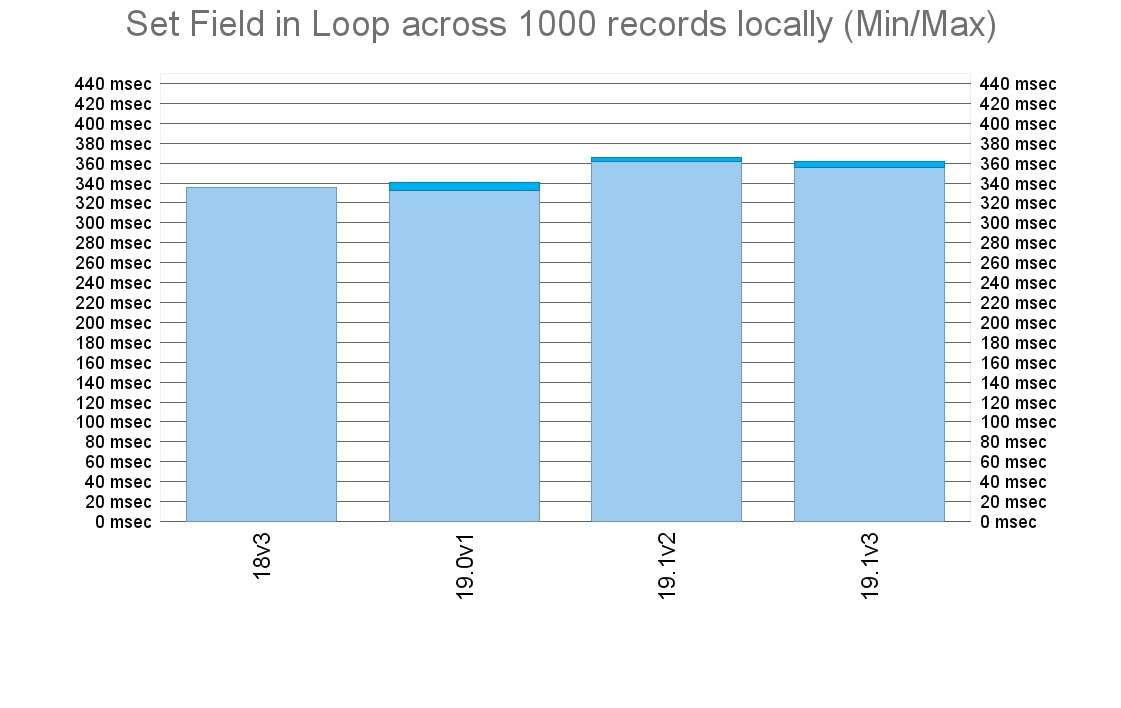
When it comes to serving a LAN client, some differences start popping up, confirming that database modifications are definitely affected by the infamous startup restoration feature introduced in FileMaker Server 18:
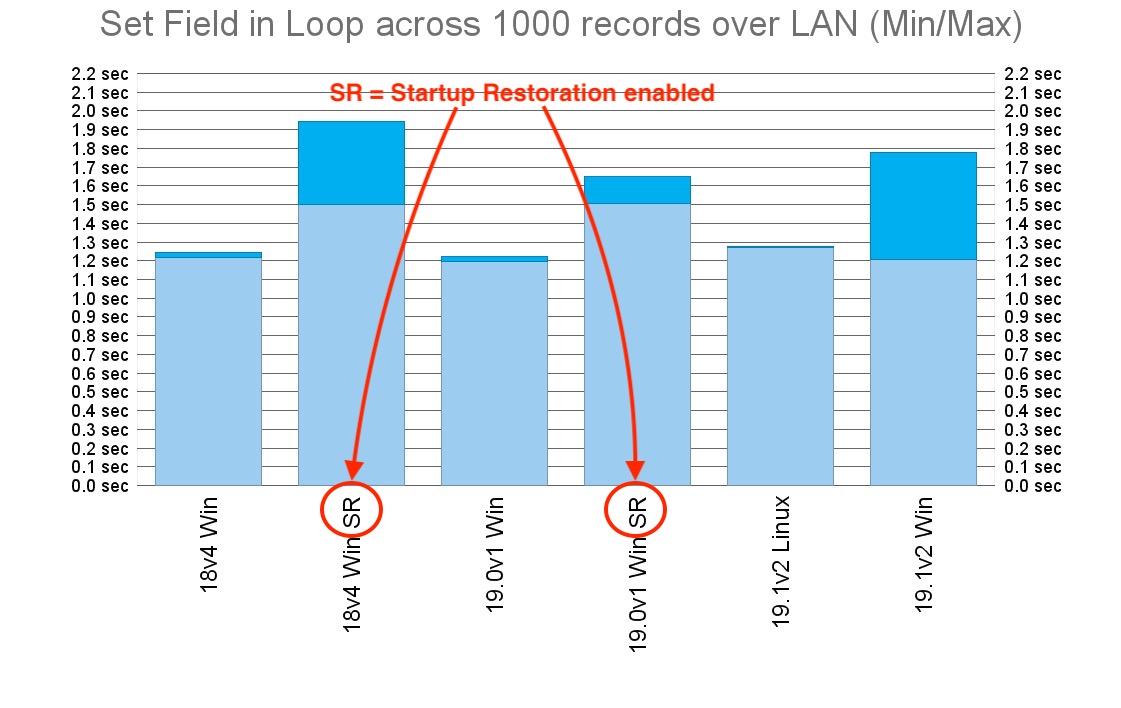
Running the test three times in a row took longer in one of the three instances I performed, but that could be affected by anything, so the light blue bars are more important here, I believe. Again, longer tests with larger data sets should reveal more.
Here’s what I got when I tried to run the same test in 5 simultaneous server-side scripts:
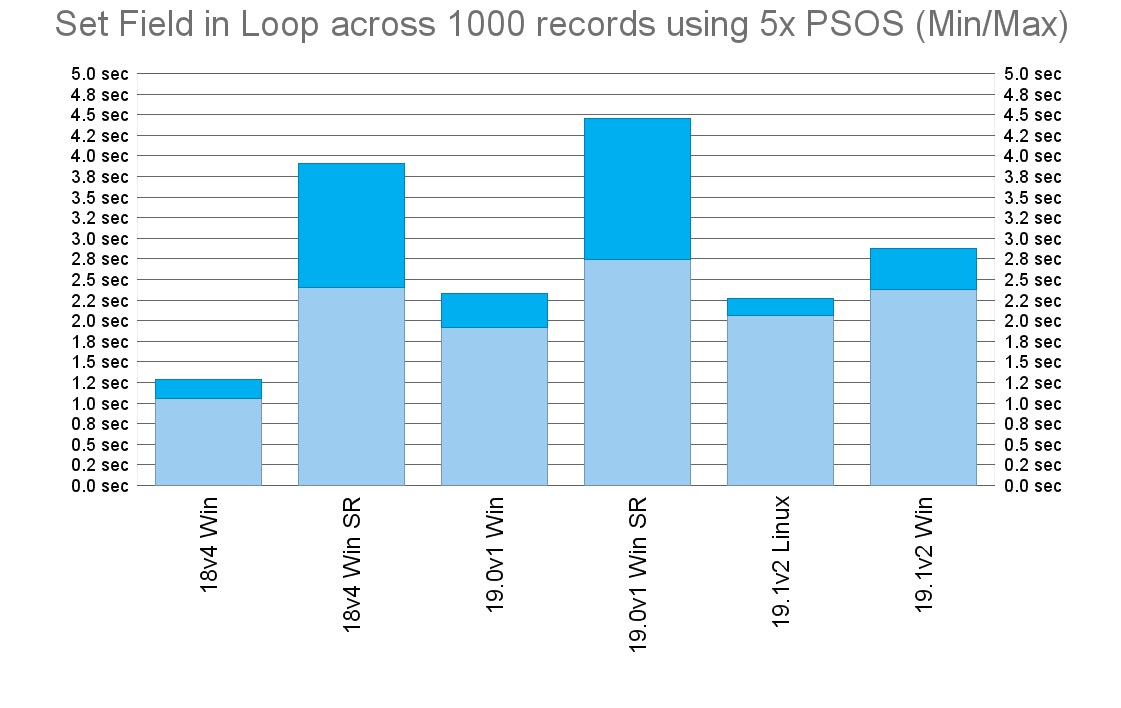
It seems, unfortunately, that FileMaker Server 18v4 with startup restoration disabled delivered the best performance in all these looped Set Field tests. But for most deployments there is a lot more read-only operations, such as performing find, than write operations, so this may be an acceptable price for better stability for many customers, since FileMaker Server 18 had some stability issues reported even with startup restoration disabled, some of which FileMaker Server 19.1.2 hopefully fixed as well.
Sorting on the host
FileMaker Server 19.1.2 brings, according to Release Notes and the List of Improvements published by Claris, some performance improvements specifically targeting read operations. I have yet to find out how performing find is affected on larger data sets, because even with 10,000 records I could not make performing indexed find take more than about a second, so my measurements were hugely biased by the overhead of staring a new server-side script with Perform Script on Server.
But I managed to make a quick test of sorting on a simulated WAN connection, using the Network Link Conditioner tool.
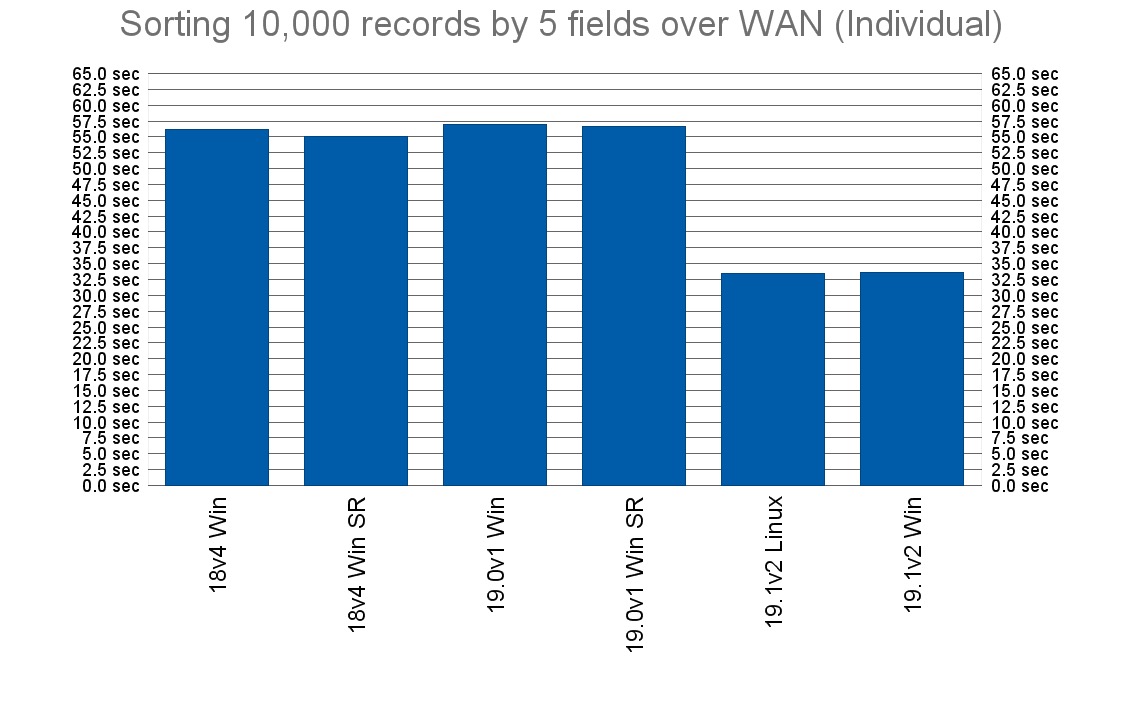
And comparing the first instance of the test across the different versions of FileMaker server seemed very promising, cutting the time needed to sort my 10,000 records from about 1 minute to just half a minute.
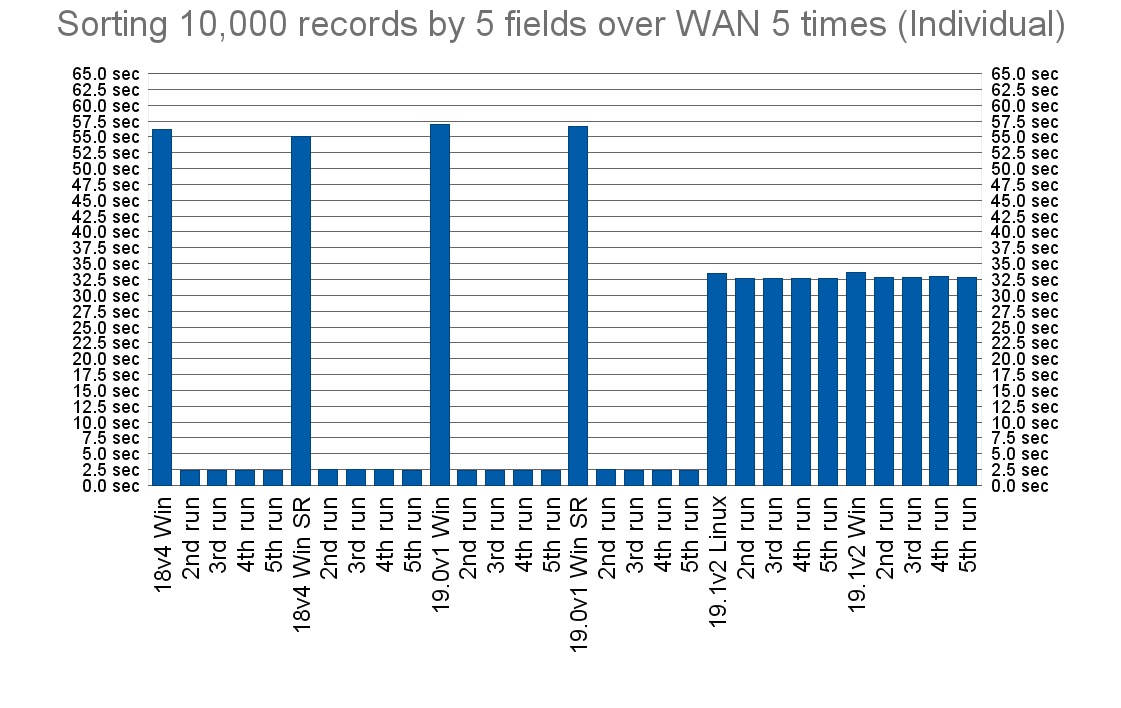
However, repeating the test 5 times in a row revealed a not-so-pleasant surprise. According to the release notes, “Starting with version 19.1.2 of FileMaker clients and FileMaker Server, FileMaker Server will perform the sort, if it's not busy”. According to my test results, basing the decision only on the question whether the server is busy is not always ideal.
Claris is hosting an Under The Hood webinar with engineers focused on FileMaker Server 19.1.2 next week. This should definitely be one of the topics discussed there, and I am almost sure there is yet another improvement going to be released soon.
Virtual List techniques compared
When we’re talking about WAN performance (i.e. connecting to the FileMaker Server over a wide area network like when working from home), I should not forget about the many different performance optimization techniques developed by all the smart minds out there over the years, among which probably the most popular is Virtual List invented by Bruce Robertson.
It’s so popular that you’ll find it mentioned almost everywhere, including the ISO Productions FileMaker Magazine, FM Forums, FileMakerHacks, FileMaker Pro Gurus, Michael Rocharde, Soliant Consulting, SeedCode, and many more blogs, forums, and websites.
The core idea of Virtual List is that you somehow efficiently collect the data you want to present to the user from the server, ideally in a single transaction, thus minimizing the impact of network latency, and display it to the user typically using unstored calculations directly from the client’s RAM (global variables). There are various ways to do that and each has some pros and cons, while the most time consuming part of this all is usually sorting the data records to present them in the right order.
So by popular demand, I have expanded my tests to include comparison of various techniques for gathering, sorting, and displaying data using Virtual List, and here’s the first result, with my 1000 records data set, running locally on all versions from 18v3 to 19.1.3 (except for the JavaScript tests).
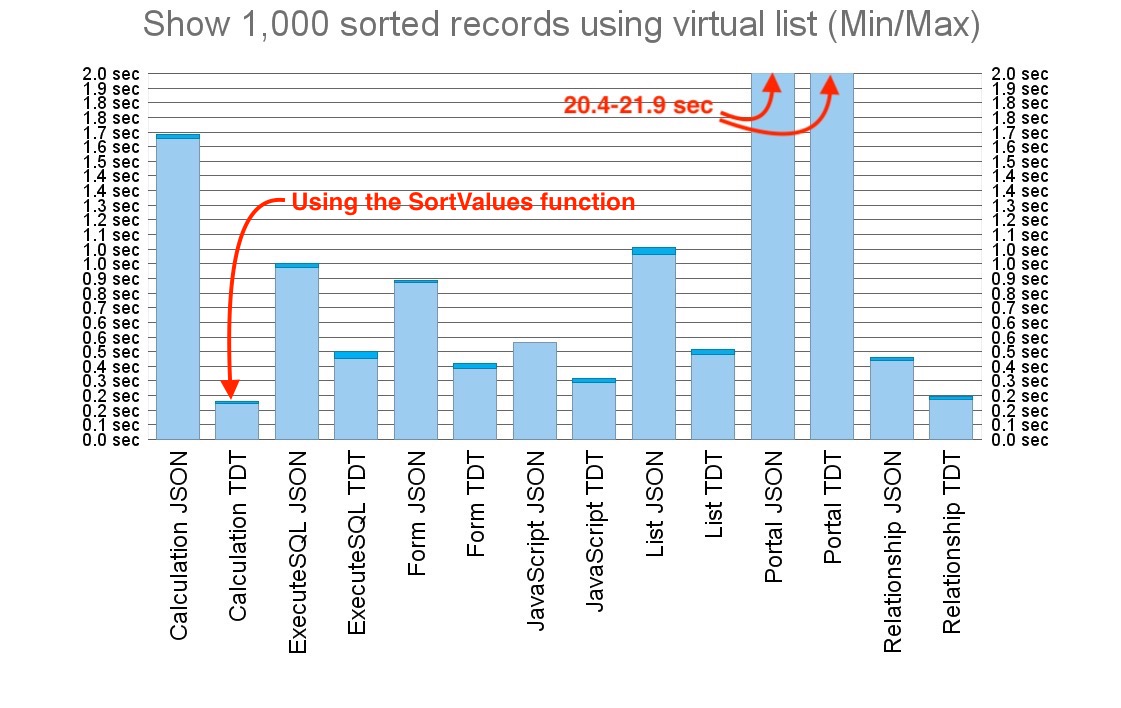
In this test, “relationship” refers to collecting the data already sorted through a sorted relationship. Also ExecuteSQL does the “ordering” when the data are gathered, so you get the virtual list already sorted. All other techniques are based on getting the data unsorted and then performing the sort on the client.
It’s obvious that sorting the virtual list through a sorted portal is completely out. You don’t want to do that. I have not verified this but I assume that’s because the unstored calculations extracting the values from the global variables get executed way too many times unnecessarily.
The final choice of the right technique then depends on your use. If you always want the data sorted by the same criteria, getting the list already sorted may be a good thing and using a sorted relationship seems to be the fastest way to do it. But you can’t use if for sub-summaries unless you re-sort the data on the client again.
If you have any reason to re-sort the data on the client, keeping the data as tab-delimited values seems to be more efficient than JSON structure. And finally when you have a reason to use JSON, I have just confirmed what I expected, which is that JavaScript is more efficient in doing that than the FileMaker’s calculation engine.
What is the most interesting discovery is that if you can let the native SortValues function do the sorting for you, then you can achieve the overall best performance, probably because the least efficient part, the sorting algorithm, is written in C++ and running as a native compiled code.
The power of JavaScript
As you probably already know, one of the new features released in FileMaker Pro 19 was the ability to perform JavaScript in web viewer and perform FileMaker Script from within a JavaScript code. FileMaker Pro 19.1.2 added one more method there, called PerformScriptWithOption. Although it may look like a minor improvement, it can actually have a huge impact because it enables you to easily use JavaScript on the client side as a powerful calculation engine. By setting the new script handling option parameter to 5, you can let a JavaScript code execute and provide its result (through a global variable) to the calling script.
To see how much performance benefit I can get from this technique, I implemented a simple (not much optimized) algorithm to find all prime numbers smaller than or equal to a given number in a few different ways. First as a simple script, then as a non-abortable script, and then as a custom function, once using recursion and once using the While function. And lastly, exactly the same algorithm as a JavaScript function. The result of my test has blown my mind so much that I added a verification that all the implementations actually return the same list of prime numbers.
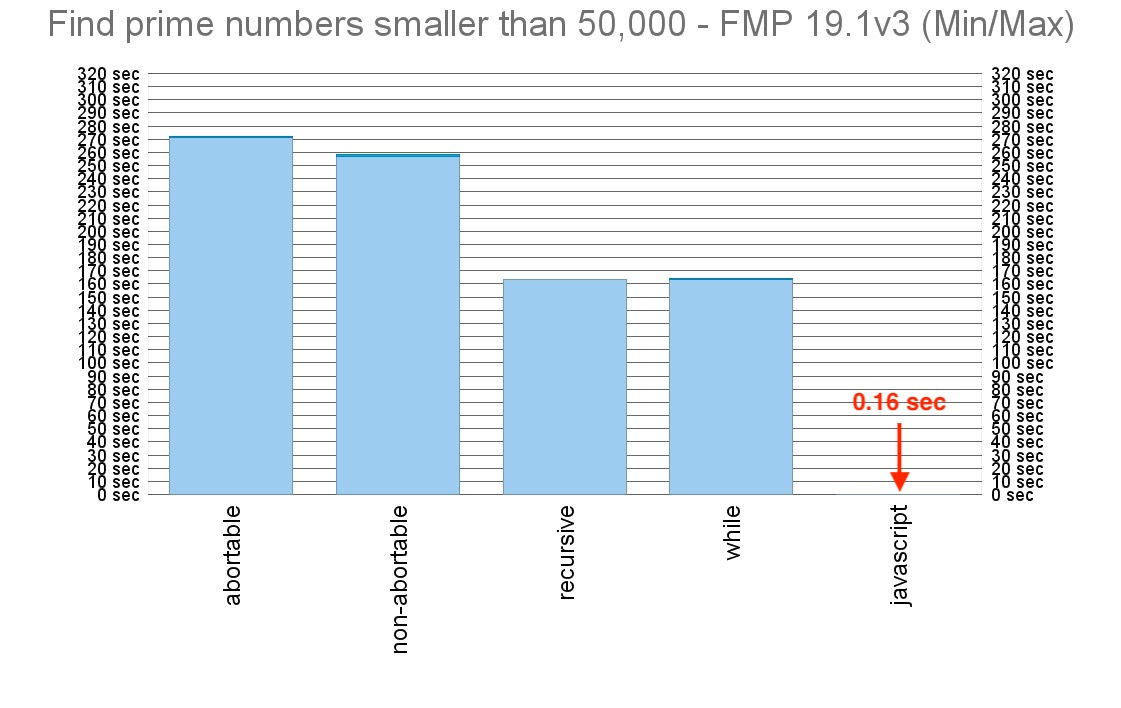
As you can see, using JavaScript is around thousand times faster for such simple math operation. And the measured time even includes going to the layout with a web viewer on it, performing the JavaScript there, running another script from within JavaScript to save its result to a global variable, and collecting the result from the global variable in the main script.
So if you want to make any complex calculations and don’t mind doing that on the client side, you may want to consider using JavaScript for that purpose, at least until Claris makes the FileMaker calculation engine significantly faster…
Let’s discuss this together
Well, however exciting or surprising this all is, it’s just the first step I made with a small data set in order to have some results quickly. I am now continuing with more tests, using larger data sets, such as 10,000 and 100,000 records, and I am going to publish more results as soon as I am able to evaluate them.
In the meantime, let me invite you to discuss these results with me in a Zoom meeting, scheduled for Thursday, November 19.